ISSN 1884-0760
GRACE TECHNICAL REPORTS
Simulation-based Graph Schema
for View Updatability Checking of Graph Queries
Keisuke Nakano
Soichiro Hidaka
Zhenjiang Hu
Kazuhiro Inaba
Hiroyuki Kato
GRACE-TR 2011–01
May 2011
CENTER FOR GLOBAL RESEARCH IN
ADVANCED SOFTWARE SCIENCE AND ENGINEERING
NATIONAL INSTITUTE OF INFORMATICS
Simulation-based Graph Schema
for View Updatability Checking of Graph Queries
Keisuke Nakano
The University of Electro-Communications
1-5-1 Chofugaoka, Chofu-shi
Tokyo 182-8585, Japan
[email protected]
Soichiro Hidaka
Zhenjiang Hu
Kazuhiro Inaba
Hiroyuki Kato
National Institute of Informatics
2-1-2 Hitotsubashi, Chiyoda-ku
Tokyo 101-8430, Japan
{
hidaka,hu,kinaba,kato
}
@nii.ac.jp
May 30, 2011
Abstract
View updating problem is concerned with translating a view update into a cor-responding update against the base data source. In our previous work, we solve the view updating problem in which both sources and views are represented by graph-structured data for general purposes. Since the solution is based on a sort of program inversion techniques, it often requires expensive computation to find the translation of view updating. The problem is that the expensive computation may be in vain when the updated view is invalid in the sense that either there is no candidate of corresponding sources or the corresponding source does not conform to user’s intention. In this paper, we present a method for checking view updata-bility in order to know whether the updated view is valid or not before computing the corresponding sources. To achieve a simple computation of view updatabil-ity checking, we introduce a new graph schema whose conformance is defined by graph simulation. Although the idea of our schema comes from the simulation-based graph schema proposed by Buneman et al., our schema can describe neces-sity of out-going edges, which was impossible in their schema. This improvement helps us to give a precise solution for view updatability checking.
1
Introduction
entry
area tel|mobile
[0-9]+ fwd [0-9]+ free
(a) UnCAL schemaS1
entry
entry entry area
tel
mobile area
tel mobile
03 1009
1729 1201 1222
free free1887 fwd
(b) Graph dataGpb
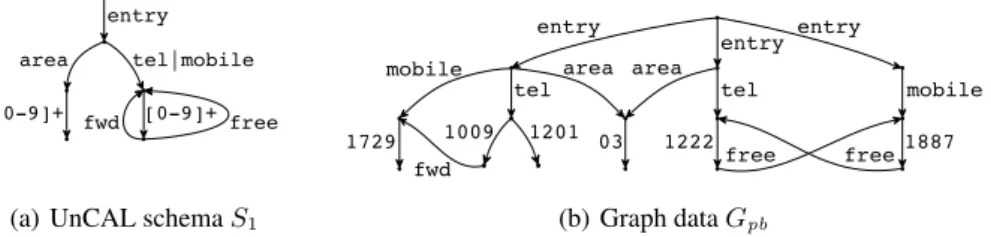
Figure 1: UnCAL graph schema of Buneman et al. and graph data
development, a relation between software components forms a graph as in UML [1] and MOF [20]. View updating on graph structures assists abidirectionalsoftware de-velopment in which we can consistently manage multiple components.
Our previous work [13] gave a solution to the view updating problem in which both sources and views are represented by graph structures. In our solution, we employed a graph query language UnCAL [6] to describe view definitions which are transforma-tions (queries) over graph structured data. One of the main advantages of UnCAL is its solid semantics foundation and efficient implementation. We do not have to care either termination or evaluation order even if an input graph data has cycle and shared nodes. Another advantage of UnCAL is that it provides a user-friendly interface lan-guage UnQL in which one can use theselect-wheresyntax like SQL to query to graph data with regular path patterns. We solved the view updating problem for UnCAL by using trace information and an automatic inversion technique [13].
One limitation of the current view updating for UnCAL is its inefficieny in dealing withinvalidview updates; it tries to propagate any view updates to the source. Since view updating often requires expensive computation, the attempt may fail and be in vain. Some updated view may have no corresponding updates. Some updated view may induce undesirable updates. These invalid view updates had better be detected before running the procedure.
In this paper, we propose a method for checking whether view updatability is valid or not before running view update translation. Our idea is to reduce the view updata-bility checking problem to computation of the range of a graph query followed by validation whether the updated view is in this range. Our contributions are two-fold. First, we introduce new graph schema, calledVU-schema, to specify a set of graph data of desirable sources. Second, we show how to compute the range of a given UnCAL query for the source graphs conforming to such schema. Since the computed range is also represented by an analogous form to our schema, we can check view updatability by inspecting if an updated view conforms to the range.
More concrerely, our graph schema issimulation-based, where the schema con-formance is checked through the existence of a graph simulation. The idea has been proposed by Buneman et al. [4] who themselves invented the graph algebra UnCAL. Figure 1 shows their graph schema S1, which we call UnCAL schema, and a graph
Gpb conforming toS1, which represents a part of some phonebook data. The Un-CAL schema is edge-labeled, similarly to UnUn-CAL graph data. The difference between schemas and graphs is that edge labels in a schema arepredicateson edge labels in graph data. In the schema S1, regular languages are used as the predicates: for in-stance,[0-9]+is satisfied by any sequence of numeral characters andtel|mobile
entry
tel|mobile entry
[0-9]+ area
[0-9]+ tel|mobile
[0-9]+ fwd [0-9]+ free
(a) VU-schemaS2
entry
(tel|mobile),(area|mobile) entry
[0-9]+ area
[0-9]+ tel|mobile
[0-9]+ [0-9]+ fwd
free
(b) VU-schemaS3
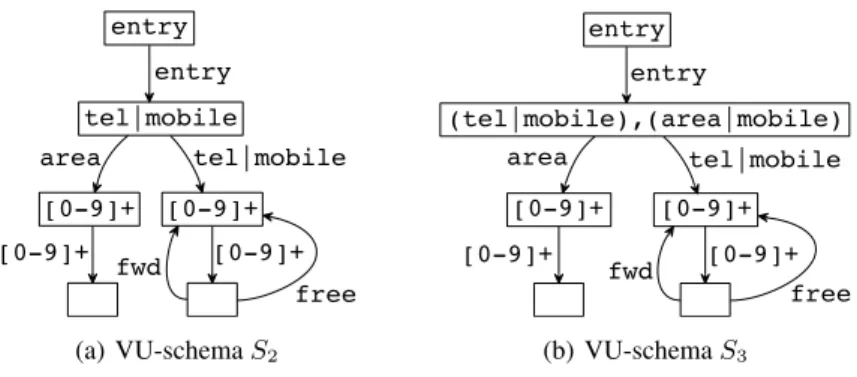
Figure 2: Examples of VU-schemas
a simulation, that is, informally, a relation from nodes in the data to those in the schema with checking the predicates on their outgoing edges.
The problem of the UnCAL schema is that they cannot force existence of some specific edges. For example, suppose thatGpbdoes not have the edge labeled with03. The graph still conforms toS1even though it is strange as a database for phone books. In extreme case, even the graph obtained by removing all edges exceptentryedges conforms toS1. The problem has already been pointed out in [4], which is caused by the unidirectionality of the simulation that is a basis of their schema conformance. It is not desirable to use the UnCAL schema in the context of view updating.
Our graph schema, VU-schema, overcomes the weakness of the UnCAL schema so that it can enforce the existence of specific edges. VU-schema is represented by a graph which has labels at not only edges but also nodes. Figure 2 shows two examples
S2 andS3of the VU-schemas. While each every label is a predicate like that of Un-CAL schemas, every node label is a finite set of predicates each of which requires the existence of an outgoing edge satisfying it in data graphs. The schema conformance of a data graph against a VU-schema is checked by finding a simulation between the data graph and the schema after assigning a set of labels of its outgoing edges to each node in the data graph. For example, the second node from the top in the VU-schemaS2has a single predicatetel|mobileas its label. It requires for the corresponding node to have an outgoing edge labeled with eithertelormobile, while the node is not required to have anareaedge. On the other hand, the second node from the top in the VU-schemaS3has a set of two predicates(tel|mobile)and(area|mobile). It requires for the corresponding node to have outgoing edges, one of which is la-beled with eithertelor mobileand another of which is labeled with eitherarea
or mobile. Therefore, the node must have bothtelandareaedges when it has nomobileedge. The UnCAL schema of Buneman’s et al. can be regarded as a spe-cial one of VU-schema in which every node is labeled with an empty set of predicates. Note that all the schemasS1,S2andS3have the same graph structure. In VU-schemas, we can represent various sorts of constraints by varying a set of predicates at the node label.
richer constraints that can enforce existence of specific edges in Section 4, and showing how the range of a graph query can be efficiently computed in Section 5. Finally, we discuss the related work in Section 6 and concludes the paper in Section 7.
2
UnCAL graphs and simulation
We start with introducing the notion of edge-labeled graphs, calledUnCAL graph[6]. In this section, we present the UnCAL graphs and a simulation on them. Throughout the paper, letLdenote a finite set of edge labels in data graphs and letMdenote a set of markers used for connecting UnCAL graphs. Every marker is written as a symbol starting with&and the setMforms a monoid(&,·)with a unit element&which is calleddefault marker.
2.1
UnCAL graphs
An UnCAL graph is a quadruple(V, E, I, O)whereV is a set of nodes,E⊆V×(L ∪ {ε})×V is a set of edges,Iis a partial function fromMtoV, andO⊆V×M. When
v =I(&x)is defined for some&x ∈ M, we callv input node; When(v,&y)∈ O
forv ∈ V, we callv output node. These nodes play an important role to synthesize graphs as shown later. Intuitively, an input node is seen as a root node of graphs and an output node is used to connect with an input node of the same marker. Every UnCAL graph has at least one input node. We writeu−→a vfor an edge(u, a, v). Fora∈ L,
E[a]denotes a subset ofEwhose edge has labela. An edge labeled with the special symbolε, calledεedge, behaves like empty transition in automata theory and is written asu99Kv. We writeu
ε∗
99K v∈ Ewhen there exist edgesu99Kv1,v1 99K vn, and
vn 99K vinE for somev1, . . . , vn. Similarly, we writeu ε∗.a
−→ vwhenu 99Kε∗ tand
t−→a vwith somet.
2.2
Extended simulation and bisimulation
The notion of simulation on UnCAL graphs is defined asextended simulationwhich is aware of markers andεedges. LetG1 = (V1, E1, I1, O1)andG2 = (V2, E2, I2, O2) be UnCAL graphs. A relation≺ ⊆V1×V2is called extended simulation if it satisfies all the following conditions:
(a) if u1 ≺ u2 and u1
ε∗.a
−→ v1, then there existsv2 ∈ V2 such that v1 ≺ v2 and
u2
ε∗.a
−→v2;
(b) ifu1≺u2andu1=I1(&x), thenu2=I2(&x);
(c) ifu1≺u2,u1
ε∗
99Kv1and(u1,&y)∈O1, thenu2
ε∗
99Kv2and(u2,&y)∈O2;
(d) ifI1(&x)is defined, thenI1(&x)≺I2(&x).
We writeG1≺G2when there exists an extended simulation between their nodes. Henzinger et al. proposes a procedure to find a simulation between nodes of graphs [12]. Figure 3 shows the procedure which is specialized for UnCAL graphs to find an extended simulation. We useprei(S)(i= 1,2) for a function which returns
{u−→a v∈ Ei |a∈ L, v ∈S}ifS is a set of nodes and{u∈Vi |u a
−→v ∈S}
input: two UnCAL graphsG1= (V1, E1, I1, O1)andG2= (V2, E2, I2, O2)with no
εedge
output: a partitionΠofV1∪E1and a simulating functionr: Π→2V2∪2E2.
Π :={V1} ∪ {E1[a]|a∈ L}.
r(V1) :=V2.
r(E1[a]) :=E2[a] (a∈ L).
whilethere existsP, Q∈Πsuch thatP∩pre1(Q)6=∅andr(P)6⊆pre2(r(Q))do
let(P′, P′′) = (P∩pre1(Q), P \pre1(Q))in
Π := (Π\ {P})∪ {P′}
r(P′) :=r(P)∩pre2(r(Q))
ifP′′6=∅thenΠ := Π∪ {P′′};r(P′′) :=r(P).
Figure 3: ProcedureFindSimfor a simulation
edge since allεedges can be eliminated in a way similar toεtransition removal for automata. See [12] for further detail of the procedure itself. For partitionΠand func-tionrwhich are an output of the procedure, we define a simulation by{(v1, v2)|U ∈
Π, v1 ∈ U ∩V1, v2 ∈ r(U)}. Although the procedureFindSimdoes not consider conditions (b),(c) and (d) on markers, they can be checked in the body of the while
loop to find an extended simulation.
When both relationRand its inverse relationR−1are extended simulations, we callRextended bisimulation. The reader may recallweak bisimulation[18] as an anal-ogous definition of bisimulation of graphs containing empty transitions like εedges of UnCAL graphs. Note that the notions of extended bisimulation and weak bisimu-lation are incomparable. The detailed comparison is found in [6]. In the rest of the paper, we say just simulation and bisimulation for extended simulation and extended bisimulation, respectively.
We say that a graph queryf isbisimulation-genericwhenf(G1)andf(G2)are bisimilar for any bisimilar UnCAL graphsG1andG2. Every graph queries represented in the graph algebra UnCAL is bisimulation-generic. UnCAL identifies graphs with any bisimilar graphs.
2.3
Finding a simulation over infinite graphs
Henzinger et al. originally presents the aforementioned procedure for finding a simu-lation overinfinitegraphs [12]. This is because that the termination of the procedure does not require finiteness of graphs. When we have a finite representation of infinite graphs with some conditions mentioned later, we can apply the procedureFindSimfor infinite graphs. Following Henzinger et al., we introduce the notion of ‘effectiveness’ of graphs.
First let us define effectiveness of classes. For a setS, a classC ⊆ 2S is called
effective representation overSwhen (1) S∈ C;
(2) a∈T is decidable for anya∈Sand anyT ∈ C;
(3) T =∅is decidable for anyT ∈ C;
For instance, a set of all regular languages is an effective representation over a set of strings, and a set of finite number of intervals of real numbers is an effective represen-tation over real numbers.
Now we define effectiveness of UnCAL graphs. We say that an UnCAL graph
G= (V, E, I, O)iseffectivewhen there exists an effective representationCoverV∪E
such that V ∈ C, E[a] ∈ C for all a ∈ L, andC is effectively closed under the
prei operation in the procedureFindSim. The procedureFindSimalways terminates when bothG1andG2are effective UnCAL graphs as shown in [12]. We can observe that it is not necessary forG2to be exactly effective. We introducepseudo-effective
representationfor classes by replacing condition (4) into
(4)′ Cis effectively closed under union and intersection, andP ⊆Qis decidable for
P, Q∈ C.
Since it only requires decidability of subsumption instead of effective closedness under complement, we can claim that pseudo-effectiveness has a relaxed form of effective-ness. As we definepseudo-effective graphsin a way similar to effective graphs, the observation above leads the following theorem as shown in [12].
Theorem 2.1 For an effective UnCAL graphG1and a pseudo-effective UnCAL graph
G2, the procedure FindSim terminates when a finite simulation exists between them.
3
UnCAL: graph algebra
We present a graph algebra UnCAL [5, 6] used for specifying graph queries on UnCAL graphs. In this section, we introduce eight constructors for UnCAL graphs and syntax and semantics of UnCAL algebra.
Every UnCAL graph can be constructed by the following eight constructors:
{} a single node graph with no edge;
{l:G} a graph with a single input node whose out-going edge is labeled withl
and points to a graphG;
G1∪G2 a graph consisting of input nodes each of which points to the corre-sponding input node ofG1andG2withεedges;
&x:=G a graph obtained by replacing input markers&zinGwith&x·&z;
&y a graph of a single output node whose marker is&y;
G1⊕G2 a graph consisting of two graphsG1andG2 whose input markers are disjoint;
G1@G2 a graph obtained by gluing each output node inG1with the correspond-ing input node inG2;
A graph algebra UnCAL is defined by adding two constructs, a conditional branch and structural recursion to the graph constructors above. The syntax of UnCAL is given by
M ::= {} | {L:M} | M∪M | &x:=M | &y
| M ⊕M | M@M | cycle(M) (CONSTRUCTORS)
| if P(L) then M else M (CONDITIONAL)
| $g (GRAPH VARIABLE)
| rec(λh$l,$gi.M)(M) (RECURSION)
L::= $l (LABEL VARIABLE)
| C (LABEL CONSTANT)
| L+L (LABEL CONCATENATION)
whereM andLrange over UnCAL expressions and label expressions, respectively. The symbolP ranges over effectively representable predicates onL. For example, it includes the predicate p=a that “whether the label equals toa” and the predicate
pa*b*that “whether the label matches a regular expressiona*b*”. Although we re-strict label operations to only concatenation in the syntax above, it is easy to introduce other simple string operation or arithmetics. An expressionrec(λh$l,$gi.M1)(M2)is a structural recursion on UnCAL graphs obtained by evaluation ofM2. The function partrec(λh$l,$gi.M1)represents a functionf satisfying
f({}) = {}
f({L:G}) = M1[$l:=L,$g:=G]@f(G)
f(G1∪G2) = f(G1)∪f(G2)
whereM1[$l :=L,$g :=G]denotes a substitution ofLandGfor$land$ginM1. Since all UnCAL graphs can be expressed in the form of{l1:G1}∪. . .∪{ln:Gn}, the
expressionf(M2)can be evaluated using the three rules no matter what is obtained by evaluation ofM2. The second clause shows that each output node of graphs obtained from M1[$l := L,$g := G]is glued with the corresponding input node of graphs obtained fromf(G)with its succeeding subgraphG. This recursive function can be implemented through memoizing the result for each subgraph even for the case where input graphs are circular because the function should return the same result for the same subgraph. Indeed, it is known that there is more efficient way to implement structural recursions of UnCAL as mentioned later. It is easy to write mutual recursive functions by using multiple input nodes.
We present the formal semantics of UnCAL expressions in Fig. 4, where[[M]]ρ
denotes a result of evaluation of an UnCAL expressionMunder an environmentρ. An environmentρis a function mapping from label variables and graph variables to labels and graphs, respectively, and the initial environment maps from a special variable$db
to the source graph. dom(f)denotes the domain of functionf andsub(G, u)denotes a subgraph ofGwhose root isu. We useµandν for Skolem functions to generate new nodes associated with their arguments. The conditions on input/output markers described in the definition of the semantics are statically inferred [6]. Hence, a setZin the definition forreccan be statically computed fromM1.
[[{}]]ρ= ({v},∅,{&7→v},∅) wherevis fresh
[[{L:M}]]ρ= ({v} ∪V,{v−→l u|u=I(&)} ∪E,{&7→v}, O)
where (V, E, I, O) = [[M]]ρ, l= [[L]]ρ, andvis fresh
[[M1∪M2]]ρ= ({vm|m∈Z} ∪V1∪V2,
{vm99Kuk |uk =Ik(m), k= 1,2} ∪E1∪E2,
{m7→vm|m∈Z}, O1∪O2)
where (V1, E1, I1, O1) = [[M1]]ρ, (V2, E2, I2, O2) = [[M2]]ρ,
Z=dom(I1) =dom(I2), andvmwithm∈Zare fresh
[[&z:=M]]ρ= (V, E,{&z·m7→v|m∈dom(I), I(m) =v}, O)
where (V, E, I, O) = [[M]]ρ
[[&z]]ρ= (v,∅,{&7→v},{(v,&z)}) wherevis fresh
[[M1⊕M2]]ρ= (V1∪V2, E1∪E2, I1∪I2, O1∪O2)
where (V1, E1, I1, O1) = [[M1]]ρ, (V2, E2, I2, O2) = [[M2]]ρ, anddom(I1)anddom(I2)are disjoint
[[M1@M2]]ρ= (V1∪V2,{v199Kv2|(v1, m)∈O1, I2(m) =v2} ∪E1∪E2, I1, O2)
where (V1, E1, I1, O1) = [[M1]]ρ, (V2, E2, I2, O2) = [[M2]]ρ,
[[cycle(M)]]ρ= ({vm|I(m) =u} ∪V,
{vm99Ku|I(m) =u} ∪ {v99Ku|(v, m)∈O, I(m) =u} ∪E,
{m7→vm|m∈dom(I)},{(v, m)∈O|m6∈dom(I)})
where (V, E, I, O) = [[M]]ρ withvm∈dom(I)are fresh
[[if P(L) then M1 else M2]]ρ=
{
[[M1]]ρ ifP([[L]])
[[M2]]ρ otherwise
[[$g]]ρ=ρ($g)
[[rec(λh$l,$gi.M1)(M2)]]ρ= (V, EfromE ∪EfromV, I, O) where G2= (V2, E2, I2, O2) = [[M2]]ρ,
(Ve, Ee, Ie, Oe) = [[M1]](ρ∪ {$l7→d,$g7→sub(G2, u)})
fore= −→d u∈E2,
Z=Ie∪Oe,
V ={µ(u, e)|u∈Ve, e∈E2} ∪ {ν(m, v)|m∈Z, v∈V2},
EfromE ={µ(u, e)−→d µ(v, e)|u−→d v∈Ee},
EfromV = {ν(m, v)99Kµ(u, e)|e=v−→ ∈E2, Ie(m) =u},
∪ {µ(u, e)99Kν(m, v)|e= −→v∈E2,(u, m)∈Oe},
Eε={ν(m, v)99Kν(m, u)|m∈Z, v99Ku∈E2},
I={n·m7→ν(m, v)|I2(n) =v, m∈Z},
O={(ν(m, v), n·m)|(v, n)∈O2, m∈Z}
[[$l]]ρ=ρ($l) [[C]]ρ=C [[f(L1, . . . , Ln)]]ρ=f([[L1]]ρ, . . . ,[[Ln]]ρ)
above, called recursive semantics. In the bulk semantics, we can evaluate arec expres-sion by two steps: first we compute a ‘local result’ for each edge of the input graph independently, then we combine those results to obtain the output graph. Buneman et al. showed the bulk semantics coincides with the recursive semantics. We adopt the bulk semantics because it makes the range computation easier.
In the bulk semantics, an UnCAL expressionrec(λh$l,$gi.M1)(M2)is evaluated in the following way, whereµandν are used for Skolem functions to generate a new node: (1) obtain a graphG2 by evaluatingM2; (2) for each edgeeinG2, evaluate
M1with binding$l and$g to the edge label and the succeeding graph, respectively. Replace each nodev withµ(v, e)in the graph to obtain a graphGe; (3) generate a
nodeν(m, v)for each nodevand markerminG2; (4) for each edgee=v−→ in
G2, connect nodeν(m, v)with input nodes of markermusingεedges; (5) for each edgee= −→vinG2, connect output nodes of markermwith nodeν(m, v)using
εedges; (6) for each input/output node of markerninG2, a nodeν(m, v)becomes input/output node of markern·min the result of therecexpression.
Example 3.1 An UnCAL expression
rec
λh$l,$gi. ifP=a($l)then{d: &}
else ifP=c($l)then&
else{$l : &}
($db)
replaces everyaedge into adedge and contract allcedges. When the variable$db
binds a graph•a//• b • c Y
Y d//•, the expression returns a graph
• b • ε " "
•d//•
ε <<
•d//
ε | | • • ε b b • ε Z Z which is
bisimilar to•d//• b • b ]
]d//•which do not haveεedges.
4
Simulation-based Graph Schema
Validity of view updating depends on whether the corresponding source satisfies con-straints specified by users. We introduce a new kind of graph schema, VU-schema, to represent the constraints. Since our graph schema has a structure analogous to UnCAL graphs, the range of an UnCAL query corresponding to a source schema is easily com-puted as shown in the next section. In this section, we first review the UnCAL graph schema [4] and its limitation. After that, we shall define our graph schema which compensates the drawback.
Both the UnCAL schema and VU-schema are given using predicates on a setL
of labels. As we use subsets ofLas the predicates, a ∈ Ameans thatasatisfies a predicateA. We fix an effective representationCoverLand consider predicates that are elements ofCin the rest of the paper.
4.1
UnCAL Schema
against an UnCAL schemaSis checked by the presence of simulation from the nodes ofGto those ofS. Since the definition of simulation assumes that the domains of edge labels of two graphs are the same, we modify the UnCAL schemaSfor its edge labels to range overLthrough the expansion procedure below before finding a simulation.
Definition 4.1 The expansion S∞ of an UnCAL schema S = (V, E, I, O)is given by an UnCAL graph(V, E∞, I, O)with a possibly infinite number of edges, where
E∞={u−→a v|u−→A v∈E, a∈A)}. We sayan UnCAL graphGconforms toS
ifG≺S∞. ✷
From the finiteness of a set of edges of an UnCAL schemaSand the effectiveness of predicates onS, we can check the schema conformance by the procedureFindSim. Note that we can use a finite representation of expansion of the UnCAL schema for implementation. We do not have to take into account its infiniteness.
We may directly compute a simulationG≺Sby replacing the condition (a) with the following one as shown in [4]:
(a)′ ifu1≺u2andu1
ε∗.a
−→v1, then there existsv2such thatv1≺v2,u2
ε∗.A −→v2, and
a∈A.
It is obvious that this definition is equivalent to the schema conformance based on expansion.
One of major advantages of the UnCAL schema is that we can easily compute the range of an UnCAL expression for a given schema. The range is obtained by the eval-uation of UnCAL expressions on the UnCAL schema in a way similar to that on Un-CAL graphs because the UnUn-CAL schema has the same structure as an UnUn-CAL graph. UnCAL schema has another advantage that we can check subsumption between two UnCAL schemas using the same simulation algorithm as the conformance checking.
Even though it has these nice properties, UnCAL Schema is not suitable to check view updatability. Buneman et al. themselves pointed out that UnCAL schema cannot enforce the presence of some label [4]. This comes from the definition of the schema conformance of a graphGagainst an UnCAL schemaS, which requires the existence of the corresponding node of (expansion of) S for all nodes ofG, but not the other way around. In this sense, all edges in the UnCAL schema are optional. UnCAL schema cannot describenecessaryedges. Since a node with no edge is simulated by any node according to the condition (a) (or (a)′), even the single-node graph with no edge conforms to any UnCAL schema. It is not desirable for view updatability checking because we always have to allow for the source graph to be updated into the single node graph that has no information at all.
4.2
VU-schema
To solve the problem that the UnCAL schema cannot describe necessity of edges, we revise the definition of the graph schema and its conformance. Our schema, called VU-schema, is represented by a graph in which not only edges but also nodes are labeled. A VU-schema is formally represented by a quintuple(V, E, I, O,⌈−⌉), whereV,E,I
andOare the same as the UnCAL schema and⌈−⌉is a labeling function from the set
V of nodes to the powerset2C(⊆22L
)of predicates.
the predicate. The schema conformance for VU-schema is defined by preprocessing both the data graph and the schema though that for the UnCAL schema is defined by preprocessing the schema only. In the following definition, for predicates (that is, subsets ofC)A1, . . . , An, A, we write{A1, . . . , An} |=Awhen(A∩A16=∅)∧ · · · ∧
(A∩An6=∅).
Definition 4.2 Thelook-ahead graphof an UnCAL graphG = (VG, EG, IG, OG)is
given by an UnCAL graph(VG∪VG◦, E◦, IG, OG), whereVG◦ ={v◦ |v ∈VG}and
E◦ ={v −→A v◦ | v ∈VG, A={a∈ L |v
a
−→ u∈EG}} ∪ {v◦
a
−→u| v −→a
u∈EG}. Theexpansionof a VU-schemaS = (VS, ES, IS, OS,⌈−⌉)is given by an
UnCAL graph(VS∪VS∞, E∞S , IS, OS)with a possibly infinite number of nodes and
edges, whereV∞
S ={v∞|v∈VS}andES∞={v A
−→v∞| ⌈v⌉ |=A, Ais finite} ∪
{v∞−→a u|v−→A u, a∈A}. We sayGconforms toSifG◦ ≺S∞. ✷
Informally, simulation is checked after transforming the UnCAL graph so that each of its nodes conveys the information of all labels of the outgoing edges in one additional edge. For a node with no outgoing edge, the empty set is assigned as an edge label in
the look-ahead graph. For example, the look-ahead graph of an UnCAL graph • •
a 33 g g g
b ++ W W W
•
is represented by •
∅
/
/•
•{a,b//}•gagg33
b ++ W W W
• ∅//• .
The relation |=in the definition above is used to enforce the presence of edges whose label satisfies a predicate of node labels of the VU-schema. The advantage of VU-schema is that we can specify both necessity and optionality of some edges. Even if an edge label does not satisfy all predicates at the corresponding node in the VU-schema, the edge is allowed to exist as far as it satisfies the label of the corresponding edge in the VU-schema.
IfS∞ is pseudo-effective for any VU-schema S, we can employ the procedure
FindSim to check the schema conformance from the effectiveness of G◦ and The-orem 2.1. In order for S∞ to be pseudo-effective, it is necessary that for any
fi-nite sets P, Q ⊆ C, the subsumption between {A ⊆ L | P |= A, Ais finite} and
{A⊆ L |Q|=A, Ais finite}is decidable. It is shown by the following lemma.
Lemma 4.3 LetP ={P1, . . . , Pm}andQ={Q1, . . . , Qn}be a finite subset ofC.
The following two statements are equivalent and both are decidable:
(I) For any finite setA⊂ L,P |=AimpliesQ|=A.
(II) For any1≤i≤n, there exists1≤j≤msuch thatPj⊆Qi.
PROOF. Since (II) immediately implies (I), it suffices to show that (I) implies (II). We prove it by contradiction. Suppose that (I) holds but (II) does not. From the negation of (II), we can take1 ≤i0≤nsuch thatPj∩Qi0 6=∅for all1 ≤j ≤m. WhenA
is a finite set obtained by selecting an element ofPj∩Qi0for eachj, it is obvious that
P |=AandQ 6|=A. This contradicts (I). We can conclude the equivalence between (I) and (II). Since (II) is decidable from the effectiveness ofC, (I) is also decidable.
simulation betweenG◦andS∞. It is easy to see the existence of the finite simulation because it suffices to consider a finite subgraph ofS∞whose edge label occurs inG◦, which is finite. Therefore, we obtain the termination of the procedureFindSimfor the schema conformance against VU-schemas.
Theorem 4.4 It is decidable whether a finite UnCAL graph conforms to a VU-schema.
5
Range computation of UnCAL
The range of an UnCAL expressionefor a VU-schemaSis a set of possible results of the evaluation ofewhere the source graph conforms toS. We compute the range in a way similar to the method for the UnCAL schema presented by Buneman et al [4]. The basic idea is that we almost directly evaluate an UnCAL expression for a given VU-schemaSby exploiting the fact that the schema has an analogous structure to an UnCAL graph. In this section, we present a method for computing the range as a VU-schema in order to check the view updatability by the VU-schema conformance. Since the current definition of VU-schema is less expressive to represent the precise range, we extend VU-schema following the method of Buneman et al.
5.1
Extension of VU-schema
Even though VU-schema is enough expressive to describe a specification of UnCAL graphs, VU-schema cannot represent the precise range of an UnCAL expression. This is because VU-schema cannot describe dependencies between subgraphs. It may re-mind the readers that the range of tree transformations for a regular tree language can-not be generally represented by any regular tree language [23]. For example, consider a VU-schema for the source ∅ [0-9]+//∅ and an UnCAL expressionrec(λh$l,$gi.{$l :
{$l : {}}})($db). The schema is conformed to by a graph of a single edge labeled
with numeral sequences; the UnCAL expression duplicates each edge from the root,
e.g., for UnCAL graphs •
3//• and •
•g1gg33
2 ++ W W W
• , the expression returns • 3//• 3//• and
• 1//•
•g1gg33
2 ++ W W W
• 2//•
, respectively. The exact range should be “a set of graphs in which the first
and the second edge from the root have the same label of a numerical sequence. There is no VU-schema representing the range, however. A na¨ıve method may overestimate the range by the VU-schema ∅ [0-9]+//∅
[0-9]+//∅, which is not precise because it
contains an impossible view •
1//• 2//•. This problem has already been pointed out
by Buneman et al. [4]. They also gave a (partial) solution to it by introducingscoped variables, which is applicable to our VU-schema.
Dependency among edge labels can be represented by shared variables. In the example above, the range is represented by
∅
[0-9]+∩ {a|a=x} //∅ [0-9]+∩ {a|a=x} //∅
(1) Vx⊆V,Ex⊆E,dom(Ix)⊆Vx,Ox⊆Vx× M, and⌈−⌉x⊆ ⌈−⌉;
(2) ifu−→A v∈Ex, thenu, v ∈Vx;
(3) ifu−→A v∈E,u6∈Vxandv∈Vx, thenv∈dom(Ix);
(4) ifm∈ MandI(m)∈Vx, thenIx(m) =I(m);
(5) ifu−→A v∈E,u∈Vxandv6∈Vx,(u, m)∈Oxfor somem∈ M;
(6) ifu−→A v∈Ex, thenxmay be used as a label constant in the setA;
(7) ifv∈VxandA∈ ⌈v⌉, thenxmay be used as a label constant in the setA;
(8) the scopes of two distinct variables are either related by subsumption or disjoint.
We callk-variable VU-schemafor an extended VU-schema withkscoped variables. The ordinary VU-schemas presented in Section 4 can be seen as 0-variable VU-schemas. The schema conformance against a k-variable VU-schema is defined by expansion and simulation in the same way as that against the ordinary VU-schema. While we expand schemas for each edge in Definition 4.1 and Definition 4.2, we expand ak-variable VU-schema for each scope at the same time. The expansion of
k-variable VU-schema is inductively defined as follows.
Definition 5.1 Let S = (V, E, I, O,⌈−⌉) be a k-variable VU-schema with scoped variablesx0, . . . , xk−1. The expansionS∞ofSis a (possibly infinite) UnCAL graph
given bySkin the following procedure:
(i) Elimination of node labels: a VU-schemaS0 is given by the expansionS∞of
S as shown Definition 4.2, wherex0, . . . , xk−1are regarded as label constants. For each variablexi, all node labels are eliminated in a scopeSxi and(S0)xi is
naturally defined.
(ii) Elimination of variables: Si+1 = (Vi+1, Ei+1, I, O)is obtained by removing a variablexifromSi= (Vi, Ei, I, O), where
Vi+1= (Vi\(Vi)xi)∪ {va |v∈(Vi)xi, a∈ L(va=vforv∈(Ii)xi)},
Ei+1= (Ei\(Ei)xi)∪ {ua l[xi:=a]
−→ va |u
l
−→v∈Exi, a∈ L}
in whichl[x:=a]denotes a label obtained by replacingxwithainl.
We saya UnCAL graphGconform toSifG◦≺S∞.
The expanded schema S∞ for k-variable VU-schema is pseudo-effective since the
number of steps for the expansion is finite. The order of variables does not affect the result of the expansion because of the scope rule (8).
Another improvement for computing of precise ranges is the introduction ofεedges labeled with predicates inC. This will be used for the range ofifexpressions in Un-CAL. Since the expansion of theseεedges replaces each predicate of their labels with labels that satisfies it,εedges labeled with the empty set are removed and the otherε
edges are left. We will show their usage in the next subsection.
because of the expressiveness of (k-variable) VU-schema, which is similar to the well-known problem as a forward typechecking of XML transformation [23]. Hence, we just show the soundness of view updatability checking that “the view is in the com-puted range if there exists the corresponding source” in this paper. We compromise the completeness which is the opposite. Since Buneman et al. have shown “the computed range is the best approximation in UnCAL schema” instead of the completeness [4, Theorem 16], we expect the same result for our VU-schema. This is left as our future work.
5.2
Range computation
We can compute the range of an UnCAL expression for a given VU-schema in the same way as the evaluation of the expression because the VU-schema has an analogous struc-ture to an UnCAL graph. Though it can be seen as a kind of abstract interpretation [8], we do not require a complicated domain such as CPO or complete lattices employed by general abstract interpretation since recursion in UnCAL can be evaluated in a simple bulk semantics as shown in Section 3.
The range of an UnCAL expression is computed as ak-variable VU-schema where
kdepends on the number ofrecconstructs in the expression. In Fig. 5 and Fig. 6, we define the range computation function Iρ and the label functionLρ with a variable
environmentρ. The environmentρis a function which maps label variables and graph variables to labels and VU-schema, respectively. The initial environment is a function
{$db 7→ Sin}with a VU-schemaSin for the specification of source graphs. Iρis a
function from UnCAL expressions tok-variable VU-schemas. Lρ is a function from
label expressions to labels. Skolem functionsµandνin the definition ofI, which are used in that of[[−]]in Fig. 4. Note that the functionI does not compute node labels which stands for necessity of edges in VU-schema. We put them for the k-variable VU-schema of the computed range after removal ofεedges, which will be explained later.
Since the ranges of most of UnCAL expressions are computed in a way similar to their semantics, we explain the range computation only forif andrecconstructs. Our range computation follows the method presented in [4]∗except that necessity of edges has to be concerned.
The range of UnCAL expressionif P(L) then M1 else M2depends on the result of the condition P(L). If we simply compute it by union of the ranges for
M1andM2, the computed range can easily be imprecise. For example, consider an UnCAL expression rec(λh$l,$gi.if P=a($l) then & else {$l : &})($db) which
represents a graph query which contracts allaedges. If we take union of ranges for
then- andelseclauses as the range of the whole expression, we lose information which edges are labeled withain the source. Therefore, we introduce specialεedges labeled with predicates corresponding the condition for theifexpression. Informally, whenP
is a predicate (that is, a set of labels) for the conditional branch, the range of the if
expression is ∅fPff22 P ,, X X X
the range ofM1 the range ofM2 .
The range of UnCAL expressionrec(λh$l,$gi.M1)(M2)is computed through the bulk semantics presented in Section 3. We first compute the rangeSM2of the argument
M2, evaluate the expression M1 for each of the edge of SM2, and combine all the
results. For each edgeeofSM2, we introduce a scoped variableze, whose scope is
Iρ({}) = ({v},∅,{&7→v},∅,−) wherevis fresh
Iρ({L:M}) = ({v} ∪V,{v−→A u|u∈dom(I)} ∪E,{&7→v}, O,−)
where (V, E, I, O,−) =Iρ(M), A=Lρ(L), andvis fresh
Iρ(M1∪M2) = ({vm|m∈M} ∪V1∪V2,
{vm
L
99Kuk |uk=Ik(m), k= 1,2} ∪E1∪E2,
{m7→vm|m∈M}, O1∪O2,−)
where (V1, E1, I1, O1,−) =Iρ(M1)
(V2, E2, I2, O2,−) =Iρ(M2)
M =dom(I1) =dom(I2)
vmwithm∈M are fresh
Iρ(&z:=M) = (V, E,{&z·m7→v|I(m) =v}, O,−)
where(V, E, I, O,−) =Iρ(M)
Iρ(&z) = ({v},∅,{&7→v},{(v,&z)},−) wherevis fresh
Iρ(M1⊕M2) = (V1∪V2, E1∪E2, I1∪I2, O1∪O2,−)
where (V1, E1, I1, O1,−) =Iρ(M1)
(V2, E2, I2, O2,−) =Iρ(M2)
I1andI2are disjoint
Iρ(M1@M2) = (V1∪V2,
{v1
L
99Kv2|(v1, m)∈O1, I2(m) =v2} ∪E1∪E2, I1, O2,−) where (V1, E1, I1, O1,−) =Iρ(M1)
(V2, E2, I2, O2,−) =Iρ(M2)
Iρ(cycle(M)) = ({vm|I(m) =u} ∪V,
{vm
L
99Ku|I(m) =u} ∪ {v
L
99Ku|(v, m)∈O, I(m) =u} ∪E,
{m7→vm|I(m) =u},{(v, m)∈O|m6∈dom(I)},−)
where (V, E, I, O,−) =Iρ(M)
Iρ($g) =ρ($g)
Iρ(if P(L) then M1 else M2) =
({vm|m∈M} ∪V1∪V2,
{vm
P∩{Lρ(L)}
99K u1|u1=I1(m)} ∪ {vm
P∩{Lρ(L)}
99K u2|u2=I2(m)} ∪E1∪E2,
{m7→vm|m∈M}, O1∪O2,−)
where (V1, E1, I1, O1,−) =Iρ(M1)
(V2, E2, I2, O2,−) =Iρ(M2)
M =dom(I1) =dom(I2)
vmwithm∈M are fresh
Iρ(rec(λh$l,$gi.M1)(M2)) = (V, EfromE∪EfromV, I, O,−)
where G2= (V2, E2, I2, O2,−) =Iρ(M2),
Ge= (Ve, Ee, Ie, Oe,−) =Iρ∪{$l7→(ze:A),$g7→sub(G2,u)}(M1)
with scoped variableszefore= A
−→ ∈E2
Z=Ie∪Oe
V ={µ(u, e)|u∈Ve, e∈E2} ∪ {ν(m, v)|m∈Z, v∈V2}
EfromE ={µ(u, e)−→A µ(v, e)|u−→A v∈Ee}
EfromV = {ν(m, v)A∩{99Kze}µ(u, e)|e=v−→ ∈A E2, Ie(m) =u}
∪ {µ(u, e)99KL ν(m, v)|e= −→v∈E2,(u, m)∈Oe}
with fresh variablesvhm,eiform∈Zande∈E2,
Eε={ν(m, v) A
99Kν(m, u)|m∈Z, v A
99Ku∈E2}
I={n·m7→ν(m, v)|I2(n) =v, m∈Z},
O={(ν(m, v), n·m)|(v, n)∈O2, m∈Z}
Lρ($l) =ρ($l), Lρ(C) =C, Lρ(f(L1, . . . , Ln)) =f(Lρ(L1), . . . ,Lρ(Ln))
Ge, to compute the range ofM1. Intuitively,zecorresponds to an edge label of a graph
conforming toSM2, which is bound to$l. This scoped variable is used to share the
edge label on computing the rangeGe, that is a ‘local’ result ofM1at the edgee. The procedure of the range computation explained so far is the same as the original one for UnCAL schemas [4]. For the range computation on VU-schema, we have to take into account node labels for necessary edges. They are put after removal of ε
edges for the computed range.
We removeεedges by replacing all occurrence ofu99Ku199K. . .99Kun A
−→v
withu−→A v, which is a traditional way forεtransition removal in automata theory. Since an εedge in VU-schemas is labeled with a subset ofL, we integrate all con-cerning labels in the replacement. For a path u 99KA1 u1
A2
99K . . . An
99K un A
−→ v in
VU-schema, we replace it withu A ′
−→vwhereA′ ={a∈A|A1 6=∅, . . . , An 6=∅}.
This replacement may be applied in multiple times for the same non-ε edge like ε
transition removal in automata theory.
Now we are ready to put node labels on the VU-schema after theεedge removal. Letube a node in the VU-schema andEua set of all outgoing edges ofu. For a scoped
variableze, we know that it comes from a non-εedgeefrom the procedure of the range
computation. WhenPedenotes a set of predicates labeled for a source node ofe, the
label⌈u⌉contains a predicate
A\ {a∈A|ze∈ ∩ P∈Pe
P}
for each edge e′ = u −→A ∈ Eu. The predicate forces to have an edge which is
originated from some necessity edges. Since these kinds of predicates is defined for each edge inEu, the cardinality of⌈u⌉coincides with that ofEu.
LetI+ be a range computing function which returns VU-schemas after adding node labels to the result of the functionI. The definition ofIbasically follows that
of [[−]]. It can be shown by simple induction on the structure of UnCAL expression
that[[M]]ρ′ conforms toI+
ρ(M)conforms to for any UnCAL expressionM and any
environmentsρandρ′ such thatρ′($g)conforms toρ($g)for all graph variables$g
andρ′($l) =ρ($l)for all label variables$l. Therefore we have the following theorem.
Theorem 5.2 LetSbe a VU-schema, Gbe a finite UnCAL graph conforming toS, andQbe an UnCAL expression. Then the UnCAL graph[[Q]]{$db7→G} conforms to
I{+$db7→S}(Q).
From the decidability of the schema conformance onk-variable VU-schema, this theorem shows that it is decidable whether there exists the corresponding source for the updated view. Note that our view updatability checking is sound but not complete, however. Since the computed range is just an approximation, there can be the case where no source graph corresponds to an updated view in the range. As aforemen-tioned, it is impossible to compute the exact range in the present VU-schema.
6
Related work
We introduce a simulation-based graph schema, VU-schema, following UnCAL schema [4]. It helps us to easily compute the range of graph queries. We improve UnCAL schema so that it can describe both necessity and optionality of edges.
There exists other work to describe a specification of graphs. Klarlund and Schwartzbach [15] proposed graph typesto describe a shape of graphs for the same purpose as ours. A graph type is represented by a tree with pointers which is analogous to a rooted graph we deal with. However, we cannot use graph types in the context of view updatability checking of UnCAL graph queries because two bisimilar graphs that UnCAL regards as equivalent ones can have different graph types.
Computing the image of graph transformation as a VU-schema can be considered as a kind of type inferences. It reminds us of a relation with a type inference for poly-morphic records [21, 19] by identifying edge labels with fields of records (or objects). Major difference is that none of them can deal with dynamically evaluated values for the names of fields. In contrast, VU-schema allows edge labels to have any kind of val-ues, e.g., strings, integers and reals which can be a result of evaluation. Additionally, their record types have the same problem on graph equivalence in UnCAL as graph types.
Another possible approach to describing graph structures is to use monadic second-order logic (MSO). Although MSO formulae can describe more flexible constraints on the shape of graphs than VU-schema, we must carefully choose an appropriate subclass of MSO theory to be decidable. Inaba et al.[14] attack the validation problem of UnCAL by reducing it into decidable MSO formulae. They cannot deal with all expressions (of UnCAL) as we can tackle, however, because that graph transformation defined by an MSO formula is linear-size increase from the definition [7], i.e., the size of outputs is linearly bounded with that of inputs. It is easy to define quadratic-size increase transformation through nested structural recursion.
7
Conclusion
We have proposed a new graph schema, VU-schema, and a novel method for com-puting the range of a graph query for sources conforming to a schema in order to check view updatability for the query. VU-schema is simulation-based in the sense that the schema conformance is checked by finding simulation relation between a given schema and graph. The idea is borrowed from UnCAL schema of Buneman et al., but have improved their schema so that it can enforce necessity and optionality of certain edges. Our framework presented in this report will be implemented as a part of our sys-tem, GRoundTram (http://www.biglab.org/), which involves view updating on graph queries.
References
[1] M. Alanen and I. Porres. Differences and union of models. InUML 2003 - The Unified Modeling Language. Model Languages and Applications. 6th Interna-tional Conference, San Francisco, CA, USA, Proceedings, volume 2863 ofLNCS, pages 2–17. Springer, 2003.
[3] A. Bohannon, J. N. Foster, B. C. Pierce, A. Pilkiewicz, and A. Schmitt. Boomerang: resourceful lenses for string data. In G. C. Necula and P. Wadler, editors,POPL ’08: ACM SIGPLAN–SIGACT Symposium on Principles of Pro-gramming Languages, pages 407–419. ACM, 2008.
[4] P. Buneman, S. Davidson, M. Fernandez, and D. Suciu. Adding structure to un-structured data. InProceedings of the 6th International Conference on Database Theory, volume 1186 ofLNCS, pages 336–350, 1997.
[5] P. Buneman, S. Davidson, G. Hillebrand, and D. Suciu. A query language and optimization techniques for unstructured data. InProceedings of ACM SIGMOD international conference on Management of Data, pages 505–516. ACM, 1996. [6] P. Buneman, M. F. Fernandez, and D. Suciu. UnQL: a query language and algebra
for semistructured data based on structural recursion.VLDB Journal: Very Large Data Bases, 9(1):76–110, 2000.
[7] B. Courcelle. Monadic second-order definable graph transductions: A survey.
Theoretical Computer Science, 126(1):53–75, 1994.
[8] P. Cousot and R. Cousot. Abstract interpretation: a unified lattice model for static analysis of programs by construction or approximation of fixpoints. In Proceed-ings of the 4th ACM SIGACT-SIGPLAN symposium on Principles of programming languages, POPL ’77, pages 238–252, New York, NY, USA, 1977. ACM. [9] U. Dayal and P. A. Bernstein. On the correct translation of update operations on
relational views.ACM Transactions on Database Systems, 7(3):381–416, 1982. [10] J. N. Foster, M. B. Greenwald, J. T. Moore, B. C. Pierce, and A. Schmitt.
Com-binators for bi-directional tree transformations: a linguistic approach to the view update problem. InPOPL ’05: ACM SIGPLAN–SIGACT Symposium on Princi-ples of Programming Languages, pages 233–246, 2005.
[11] G. Gottlob, P. Paolini, and R. Zicari. Properties and update semantics of consistent views.ACM Transactions on Database Systems, 13(4):486–524, 1988.
[12] M. R. Henzinger, T. A. Henzinger, and P. W. Kopke. Computing simulations on finite and infinite graphs. InProceedings of 20th Symposium on Foundations of Computer Science, pages 453–462. IEEE Computer Society Press, 1995. [13] S. Hidaka, Z. Hu, K. Inaba, H. Kato, K. Matsuda, and K. Nakano.
Bidirection-alizing graph transformations. InACM SIGPLAN International Conference on Functional Programming, pages 205–216. ACM, 2010.
[14] K. Inaba, S. Hidaka, Z. Hu, H. Kato, and K. Nakano. Sound and complete valida-tion of graph transformavalida-tions. Technical Report GRACE-TR-2010-04, GRACE Center, NII, 2010.
[15] N. Klarlund and M. I. Schwartzbach. Graph types. InPOPL ’93: Proceedings of the 20th ACM SIGPLAN-SIGACT symposium on Principles of programming languages, pages 196–205, New York, NY, USA, 1993. ACM.
[17] K. Matsuda, Z. Hu, K. Nakano, M. Hamana, and M. Takeichi. Bidirectionaliza-tion transformaBidirectionaliza-tion based on automatic derivaBidirectionaliza-tion of view complement funcBidirectionaliza-tions. In12th ACM SIGPLAN International Conference on Functional Programming (ICFP 2007), pages 47–58. ACM Press, Oct. 2007.
[18] R. Milner. Communication and concurrency. Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 1989.
[19] A. Ohori. A polymorphic record calculus and its compilation. ACM Trans. Pro-gram. Lang. Syst., 17(6):844–895, 1995.
[20] OMG. Metaobject facility (MOF) specification. http://www.omg.org/ docs/formal/02-04-03.pdf, 2002.
[21] D. R´emy. Type inference for records in natural extension of ML. InTheoretical aspects of object-oriented programming: types, semantics, and language design, pages 67–95. MIT Press, Cambridge, MA, USA, 1994.
[22] G. Rozenberg, editor. Handbook of graph grammars and computing by graph transformation: volume I. foundations. World Scientific Publishing Co., Inc., River Edge, NJ, USA, 1997.